








CppWebServer
 Updated Time
Updated Time
 Category
Category
 Tags
Tags
参考仓库 30dayMakeCppServer
Socket
对于服务器而言,需要建立一个套接字,对外提供一个网络通信接口。对于
Linux 来说,套接字只是一个文件描述符,也就是一个 int
类型的值。对应的系统调用为:
|
- 第一个参数:IP 地址类型,
AF_INET表示使用 IPv4,AF_INET表示使用 IPv6; - 第二个参数:数据传输方式,
SOCK_STREAM表示流格式,多用于 TCP。SOCK_DGRAM表示数据报格式,多用于 UDP; - 第三个参数:协议,0 表示根据前面两个参数自动推断,分别可以设置为
IPPROTO_TCP和IPPROTO_UDP;
对于客户端而言,需要将一个套接字绑定到一个指定的 ip
和端口上,对应的结构体为 sockaddr_in:
|
设置地址簇、IP 地址和端口: serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
serv_addr.sin_port = htons(8888);
将 socket 地址与文件描述符绑定:
|
 Question 为什么要转化为通用socket地址sockaddr
Question 为什么要转化为通用socket地址sockaddr
TODO
最后需要使用 listen 函数监听这个 socket
窗口,第二个参数是 listen 的最大监听队列长度,系统建议的最大值是
SOMAXCONN 被定义为 128。
|
要接受一个客户端的链接,需要使用 accept
函数,对于每一个客户端,在接收连接时也需要保存客户端的 socket
地址信息:
|
客户端的逻辑比较类似,把 accept 换成 connect 即可,下面是完整的代码:
#include <arpa/inet.h>
#include <cstring>
#include <stdio.h>
#include <sys/socket.h>
struct sockaddr_in serv_addr;
int main()
{
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
bzero(&serv_addr, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
serv_addr.sin_port = htons(8888);
bind(sockfd, (sockaddr*)&serv_addr, sizeof(serv_addr));
listen(sockfd, SOMAXCONN);
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
bzero(&client_addr, sizeof(client_addr));
int client_sockfd = accept(sockfd, (sockaddr*)&client_addr, &client_addr_len);
printf("new client fd %d! IP: %s Port: %d\n", client_sockfd, inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port));
return 0;
}
#include <arpa/inet.h>
#include <cstring>
#include <sys/socket.h>
struct sockaddr_in serv_addr;
int main()
{
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in serv_addr;
bzero(&serv_addr, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
serv_addr.sin_port = htons(8888);
connect(sockfd, (sockaddr*)&serv_addr, sizeof(serv_addr));
}
错误处理
在 《Effective C++》条款 8 种提到,别让异常逃离析构函数。对于 Linux 系统调用,常见的错误提示方式是使用返回值和设置 errno 来说明错误类型。通常来说,当一个系统调用返回 -1,说明有 error 发生。为了方便处理错误,可以封装一个错误处理函数:
|
read & write
当建立一个 socket 时,就可以使用 <unistd.h>
头文件中的 read 和 write
来进行网络接口的数据读写操作了。
服务端: while (true) {
char buf[1024];
bzero(&buf, sizeof(buf));
ssize_t read_bytes = read(client_sockfd, buf, sizeof buf);
if (read_bytes > 0) {
printf("message from client fd %d: %s\n", client_sockfd, buf);
write(client_sockfd, buf, sizeof buf);
} else if (read_bytes == 0) {
printf("client fd %d disconnected\n", client_sockfd);
close(client_sockfd);
break;
} else if (read_bytes == -1) {
close(client_sockfd);
errif(true, "socket read error");
}
}
close(sockfd);
客户端类似,相同的实现方式: while (true) {
char buf[1024];
bzero(&buf, sizeof buf);
scanf("%s", buf);
ssize_t write_bytes = write(sockfd, buf, sizeof buf);
if (write_bytes == -1) {
printf("socket already disconnected, can't write any more");
break;
}
bzero(&buf, sizeof buf);
ssize_t read_bytes = read(sockfd, buf, sizeof buf);
if (read_bytes > 0) {
printf("message from server: %s\n", buf);
} else if (read_bytes == 0) {
printf("server socket disconnected\n");
} else if (read_bytes == -1) {
close(sockfd);
errif(true, "socket read error");
}
}
目前为止实现了一个最简单的 echo 服务器,并且拥有最基本的错误处理。但是服务器只能处理一个客户端。
epoll
IO 多路复用的基本思想是事件驱动,服务器同时保持多个客户端 IO 连接,当这个 IO 上有可读或可写事件发生时,表示这个 IO 对应的客户端在请求服务器的某项服务,此时服务器响应该服务。在 Linux 系统中,IO 多路复用使用 epoll 来实现。
 Tip epoll
Tip epoll
TODO
epoll 主要由三个系统调用组成,创建一个 epoll 文件描述符并返回,失败返回 -1:
|
epoll 监听的事件描述符会放在一棵红黑树上,将要监听的 IO 放入红黑树中,就可以监听 IO 事件:
|
其中 sockfd 表示要添加的 IO 文件描述符,ev 是一个 epoll_event 结构体,其中的 events 表示事件,data 是一个用户数据:
|
epoll 默认采用 LT 触发模式,即水平触发,只要 fd 上有事件,就会一直通知内核。这样可以保证所有事件都得到处理、不容易丢失,但可能发生的大量重复通知也会影响 epoll 的性能。如使用 ET 模式,即边缘触法,fd 从无事件到有事件的变化会通知内核一次,之后就不会再次通知内核。
|
其中 events 是一个 epoll_event 结构体数组,maxevents 是可供返回的最大事件大小,一般是 events 的大小,timeout 表示最大等待时间,设置为 -1 表示一直等待。
使用的客户端代码没有改动,服务端加入多路复用的逻辑:
|
Cpp 面向对象
目前为的实现和 CPP 没有多大关系,和一个 C 程序相同,最低级的模块化就是构建一个类。这部分的内容把 Socket、Epoll 等全部封装成类。
这里只贴一个 github
channel
在目前的实现中,将一个文件描述符添加到 epoll
红黑树,当该文件描述符上有事件发生时,获取对应的文件描述符并处理它的事件。如果一个服务器提供了不同的服务,比如
HTTP、FTP,那么不同的文件描述符需要有不同的处理逻辑,仅仅通过一个文件描述符来区分会很麻烦。
|
epoll_event 中的 data 是一个 union
类型,可以存储一个指针。而通过指针,可以指向任何一个地址块的内容,可以是一个类的对象,这样就可以将一个文件描述符封装成一个
Channel 类,一个 Channel
类始终只负责一个文件描述符,对不同的服务、不同的事件类型,都可以在类中进行不同的处理,而不是就仅仅拿到一个
int 的文件描述符。
|
每个文件描述符会被分配到一个 Epoll 类,用一个 ep
指针来指向。另外两个是事件变量,events
表示希望监听这个文件描述符的哪些事件,因为不同事件的处理方式不一样。revents
表示在 epoll 返回该 Channel
时文件描述符正在发生的事件。inEpoll 表示当前 Channel 在
epoll 中,为了注册的时候方便区分使用 EPOLL_CTL_ADD 还是
EPOLL_CTL_MOD。
在 new 一个 Channel 的时候,因为还没有设置
events,不会监听该 Channel
上的任何事件发生。如果希望监听,则需要调用
enableReading():
|
将要监听的 events 设置为读模式并采用 ET 模式,然后在 ep
指针指向的 epoll 红黑树中更新 Channel。
|
虽然现在是通过 Channel 来注册监听,但是没有将事件处理改为
Channel 回调函数的方式,这实际上是错误的。这一版本的代码
事件驱动
从代码上可以看到,不管是接受客户端连接还是处理客户端连接,都是围绕 epoll 来编写的,epoll 是整个程序的核心,服务器做的事情就是监听 epoll 上的事件,然后对不同事件类型进行不同的处理。这种以事件为核心的模式又叫事件驱动。目前几乎所有的现代服务器都是事件驱动的。
事件驱动不是服务器开发的专利,事件驱动是一种设计应用的思想、开发模式,而服务器是根据客户端的不同请求提供不同的服务的一个应用实体。
服务器有两种经典的开发模式,Reactor 和 Proactor 模式。
Question 什么是Reactor和Proactor
关于 Reactor 和 Proactor 的内容请看附录。
Linux 内核系统调用的设计更加符合 Reactor 模式,所以绝大部分高性能服务器都采用 Reactor 模式进行开发。下面就将上述实现的服务器改造成 Reactor 模式。
首先将服务器抽象成一个 Server 类,这个类中有一个
main-Reactor,核心是一个
EventLoop,这是一个事件循环,添加要监听的事件到这个事件循环内,每次有事件发生就会通知,然后根据不同的描述符、事件类型进行处理(回调函数)。newConnection()
被绑定到服务器 socket 上,handleReadEvent()
被绑定到新接收的客户端 socket 上。
目前实现的 Reactor 模式并不是一个完整的 Reactor 模式,处理事件请求仍然在事件驱动的线程里。这版本的代码
Acceptor
目前所有的逻辑都写在了 Server 类里,但是
Server
类作为一个服务器类,应该更抽象、更通用。对于每一个事件,不管提供什么样的服务,首先需要做的事都是调用
accept() 函数接受这个 tcp 连接。然后将 socket
文件描述符添加到 epoll。当这个 IO 有事件发生的时候,再对此 tcp
连接提供相应的服务。
因此可以分离接受连接这一模块,添加一个 Acceptor: -
类存在于事件驱动 EventLoop 类中,也就是 Reactor 模式的
main-Reactor; - 类中的 socket fd 就是服务器监听的 socket fd,每一个
Acceptor 对应一个 socket fd; - 类通过一个独有的 Channel
负责分发到 epoll,该 Channel 的事件处理函数 handleEvent()
会调用 Acceptor 中的接受连接函数来新建一个 TCP 连接;
|
新建连接的逻辑交给 Acceptor 类中。逻辑上新 socket
建立后和之前监听的服务器 socket 没有任何关系了,TCP 连接和 Acceptor
一样。新的 TCP 连接应该由 Server
类来创建并管理生命周期,而不是
Acceptor。对于所有的服务,都要使用 Acceptor
来建立连接。
为了实现这一设计,可以用两种方式: -
使用传统的虚类、虚函数来设计一个接口 - C++11
的特性:std::function、std::bind、右值引用、std::move
等实现函数回调
这里使用 functional 来实现回调函数。在
Acceptor 中定义一个新建连接的回调函数:
|
在新建连接时,只需要调用这个回调函数: void Acceptor::acceptConnection() { newConnectionCallback(sock); }
这个版本的代码
tcp 连接
对于 TCP
协议,三次握手新建连接后,这个连接会一直存在,直到四次挥手断开连接,因此,可以把
TCP 连接抽象成一个 Connection 类,这个类有以下特点: -
类存在于事件驱动 EventLoop 中,也就是 Reactor 模式的
main-Reactor; - 类中的 socket fd 就是客户端的 socket fd,每一个
Connection 对应一个 socket fd; - 每一个类的实例通过一个独有的 Channel
负责分发到 epoll,该 Channel 的事件处理函数 handleEvent()
会调用 Connection 中的事件处理函数来响应客户端请求;
Coonection 类和 Acceptor 类十分相似,都是由
Server 直接管理,由一个 Channel 分发到
epoll,通过回调函数处理相应事件。唯一不同的是,Acceptor
类处理的逻辑被放到了 Server 中,而 Connection
没有必要这么做。
一般而言,一个高并发服务器只会有一个 Acceptor
用于接受连接(也可以有多个),但可能会同时拥有成千上万个 TCP
连接,需要把这些连接都保存起来。
|
接受连接后,服务器把该 TCP 连接保存在一个 map
中,键为该连接客户端的 socket fd,值为指向该连接的指针。
这个版本的代码
Buffer
在目前的视线中,使用的读缓冲区大小为 1024,每次从 TCP 缓冲区读取 1024 大小的数据到缓冲区,然后发送给客户端。但是在逻辑上有很多不合理的地方,比如并不知道客户端信息的真正大小是多少,只能以 1024 的读缓冲区去读 TCP 缓冲区。也不能一次性读取所有客户端数据,再统一发给客户端。
为每一个 Connection
类分配一个读缓冲区和写缓冲区,从客户端读取来的数据都存放在读缓冲区里。
这个版本的代码
线程池
目前的架构少了一个最重要的模块「线程池」。当 socket fd 有事件时,应该分配一个工作线程,由这个工作线程处理 fd 上面的事件。目前 fd 上面的事件都是由主线程(EventLoop)处理的。每一个 Reactor 只应该负责事件分发,而不应该负责事件处理。
线程池有很多种实现方式,最简单的一种是每有一个新任务、就开一个新线程执行。这种方式最大的缺点就是线程数不固定。为了避免服务器负载不稳定,采用固定线程数的方法,即启动固定数量的工作线程,一般是 CPU 核数,然后将任务添加到任务队列,工作现场不断主动取出任务队列的任务执行。
关于任务队列,需要注意两点: 1. 在多线程环境下任务队列的读写操作都应该考虑互斥锁; 2. 任务队列为空时 CPU 不应该不断轮询耗费 CPU 资源;
线程池定义如下:
|
主要是线程池的初始化构造函数: ThreadPool::ThreadPool(int size) : stop(false) {
for (int i = 0; i < size; ++i) {
threads.emplace_back(std::thread([this]() {
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(tasks_mtx);
cv.wait(lock, [this]() { return stop || !tasks.empty(); });
if (stop && tasks.empty()) return;
task = tasks.front();
tasks.pop();
};
task();
}
}));
}
}
需要添加任务时,只需要将任务添加到任务队列: void ThreadPool::add(std::function<void()> func) {
{
std::unique_lock<std::mutex> lock(tasks_mtx);
if (stop) {
throw std::runtime_error(
"ThreadPool already stop, can't add task any more");
}
tasks.emplace(func);
}
cv.notify_one();
}
这样实现了一个最简单的线程池,当 Channel
类有事需要处理时,将这个事件处理线程池,主线程 EventLoop
就可以继续进行事件循环,而不在乎某个 socket fd 上的事件处理。
这个版本的代码
这个线程池只是为了满足需要构建出的最简单的线程池,存在很多问题。比如,由于任务队列的添加、取出都存在拷贝操作,线程池不会有太好的性能,正确的做法是使用右值移动、完美转发等阻止拷贝。另外线程池只能接受
std::function<void()>
类型的参数,所以函数参数需要事先使用
std::bind(),并且无法得到返回值。
为了解决这些问题,需要改变的是将任务添加到任务队列的 add
函数。需要使用 add
函数前不需要手动绑定参数,而是直接传递,并且可以得到任务的返回值。
额外修复了之前版本的一个缺点,对于
Acceptor,接受连接的处理时间较短、报文数据极小,并且一般不会有特别多的新连接在同一到达,所以
Acceptor 没有必要采用 epoll ET
模式,也没有必要用线程池。由于不会成为性能瓶颈,为了简单最好使用阻塞式
socket。
这个版本的代码
附录
Reactor
如果要让服务器处理多个客户端,那么最直接的方式就是为每一条连接创建线程。创建进程也是可以的,原理是一样的,进程和线程的区别在于线程比较轻量一些,线程的创建和切换成本要小一些。处理完业务逻辑后,随着连接关闭后线程也要销毁了,不停的创建和销毁也会造成资源浪费,而且如果要连接几万条连接,创建几万个线程去应对也是不现实的。
IO 多路复用技术会用一个系统调用函数来监听所有关心的连接,也就是在一个监控检查里面监控很多的连接。对 IO 多路复用在进行一层封装,就变成了 Reactor 模式,也叫 Dispatcher 模式。IO 多路复用监听事件,收到事件后,根据事件类型分配给某个进程/线程。
Reactor 模式主要由 Reactor 和处理资源池两个核心部分组成,负责的事情如下: - Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件; - 处理资源池负责处理事件;
Reactor 的数量可以是一个,也可以是多个。处理资源池可以是单个线程,也可以是多个线程。所以经过排列组合就可以得到四种模型。
其中三种比较经典: - 单 Reactor - 单线程; - 单 Reactor - 多线程; - 多 Reactor - 多线程;
「单 Reactor - 单线程」模型:
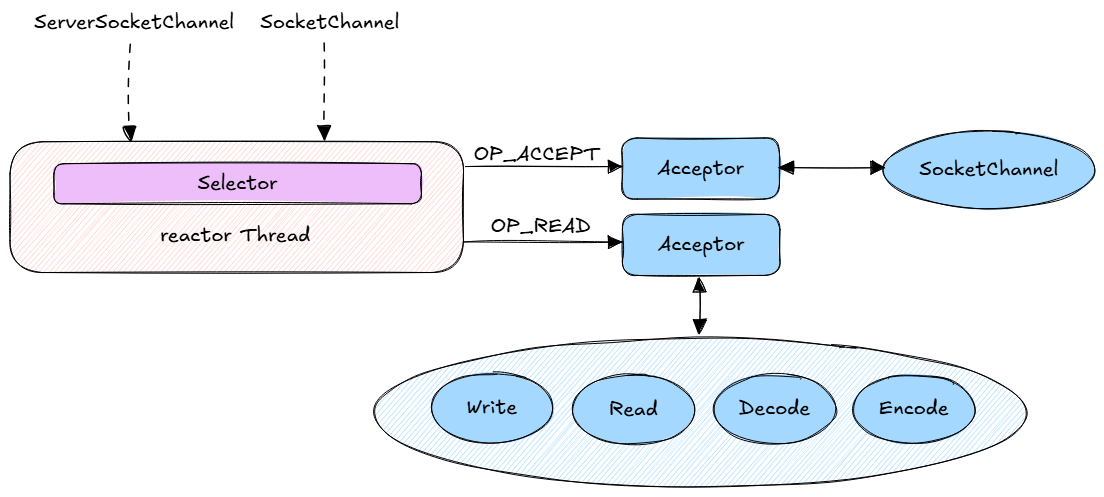
「单 Reactor - 多线程」模型:
