








kube-proxy解析
 Updated Time
Updated Time
 Category
Category
 Tags
Tags
iptables
环境准备
- 宿主机操作系统:Linux ubuntu 22.04.5
- 启动三个 Docker 容器来模拟物理主机
Docker 启动的应用程序为一个 Golang Http Server:
var (
port *int = flag.Int("port", 8080, "")
)
func main() {
flag.Parse()
mux := http.NewServeMux()
mux.HandleFunc("/hello", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte(fmt.Sprintf("hello wolrd, i'm %d", *port)))
})
mux.HandleFunc("/index", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("<h1>Hello World</h1>"))
})
l, _ := net.Listen("tcp", fmt.Sprintf(":%d", *port))
http.Serve(l, mux)
}
# 使用官方 Go 镜像作为构建阶段
FROM golang:1.24-alpine AS builder
# 设置工作目录
WORKDIR /app
# 复制源代码
COPY . .
# 构建应用程序
RUN go build -o main .
# 使用轻量级 Alpine 镜像作为运行阶段
FROM alpine:latest
# 创建非 root 用户运行应用
RUN addgroup -S appgroup && adduser -S appuser -G appgroup
# 设置工作目录
WORKDIR /app
# 从构建阶段复制可执行文件
COPY --from=builder /app/main .
# 设置非 root 用户
USER appuser
# 暴露端口(与代码中的默认端口 8080 对应)
EXPOSE 8080
# 运行应用程序
CMD ["./main"]
启动命令:
|
测试连通性:
|
netfilter
iptables 是运行在用户空间的软件,实际上真正工作是内核当中的 netfilter 模块。netfilter 专门管理网络数据包的处理和转发。
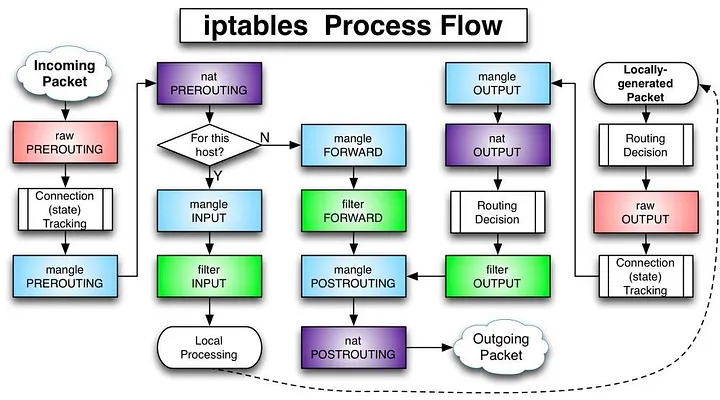
netfilter
中有三个重要的概念:表(table)、链(chain)和规则(rule)。表指的是不同类型的数据包处理流程,如
filter 表表示进行数据包过滤,而 nat
表针对连接进行地址转换操作。每个表中又可以存在多个链,系统按照预订的规则将数据包通过某个内置链,例如将从本机发出的数据通过
OUTPUT
链。在链中可以存在若干规则,这些规则会被逐一进行匹配,如果匹配,可以执行相应的动作,如修改数据包,或者跳转。从图中可以看出
netfilter 有四种表:raw、nat、filter、mangle。
filter 表是默认的表,如果不指明表则使用此表。其通常用于过滤数据包。其中的内置链包括:
- INPUT,输入链。发往本机的数据包通过此链。
- OUTPUT,输出链。从本机发出的数据包通过此链。
- FORWARD,转发链。本机转发的数据包通过此链。
nat 表用于地址转换操作。其中的内置链包括:
- PREROUTING,路由前链,在处理路由规则前通过此链,通常用于目的地址转换(DNAT)。
- POSTROUTING,路由后链,完成路由规则后通过此链,通常用于源地址转换(SNAT)。
- OUTPUT,输出链,类似 PREROUTING,但是处理本机发出的数据包。
当网络协议栈收到了一个网络包,首先经过 PreRouting 链的 nat 表,在这里会做 DNAT(Destination NAT)。之后会判断目的 ip 地址是不是本机,这里的本机指的是本机的任意 IP 地址,不仅仅是 localhost。如果是的话送入 Input 链,做 Local Precessing。
如果不是本机,也就是说数据包只是经过了该设备,最终还是要交给某一个 interface 来传递出去。那么就需要经过 Forward 和 PostRouting 链。在 PostRouting 的 nat 表可能会做 SNAT(Source NAT),变更数据包的源地址。其中有两种改写方式,SNAT 将包的 source address 修改为固定的 IP address,MASQUERADE 将包的 source address 修改为发送出去网络设备的 IP address。
如果一个包是本机产生的(Locally-generated Packet),会先进行 routing decision,决定走哪条路由,再交给 Output 链。在经过 Output 链,进入 PostRouting 之前,还会进行一次 re-route 的检查,因为 Output 的 nat 表可能会做 DNAT,所以需要重新再计算一次路由。
命令
安装: apt install iptables
查看本机 iptables 配置: # -v 是完整显示
iptables -L -v
Docker 网络模型分析
通过 ifconfig 指令可以看到 docker 默认创建了一张虚拟网卡
docker0,是 Docker 默认的 bridge 网络接口。可以把 bridge
当作是一个二层的交换机,负责数据包的传递。而接在交换机上的是网线,联通的两个网络设备,这里用的是
veth 来连接。
|

在环境准备中,我们启动了三个容器,那么对应的网桥上一个连接三个
veth,可以通过 brctl 工具来查看:
|
通过容器的 Pid 来查看容器所对应的 ip 地址: $ docker inspect 701f | grep Pid
$ nsenter -t 227400 -n ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether f6:76:82:03:3c:11 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
可以看到当前的容器的 ip 是 172.17.0.4,而绑定的 veth 是
if10,对应的是第 10 个索引的 veth,下一步是查看一下对应的 if10 是哪一个
veth pair: $ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:41:3b:72 brd ff:ff:ff:ff:ff:ff
altname enp0s5
altname ens5
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether aa:ee:0b:3b:75:4b brd ff:ff:ff:ff:ff:ff
8: vethfb4a123@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether d6:83:3c:c4:92:ea brd ff:ff:ff:ff:ff:ff link-netnsid 0
9: veth36c276d@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether ae:4e:3c:6b:41:55 brd ff:ff:ff:ff:ff:ff link-netnsid 1
10: veth09b65e0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 72:a3:1a:06:1e:87 brd ff:ff:ff:ff:ff:ff link-netnsid 2
那么再启动了三个容器之后,docker 对 iptables 的规则也做了相应的添加和修改。用指令去查看 netfilter 中 nat 表的内容:
|
一个网络包发送到该主机上,首先要经过 PreRouting 链,根据 nat
表中的内容,决定是不是要做 DNAT。那么此时会去 DOCKER
链去匹配,可以看到这里有三条匹配规则。
- 如果是 tcp 协议,且目的端口是 8003 则转发到
172.17.0.2:8080 - 如果是 tcp 协议,且目的端口是 8002 则转发到
172.17.0.3:8080 - 如果是 tcp 协议,且目的端口是 8001 则转发到
172.17.0.4:8080
接下来通过网络抓包的方式,来查看 iptables 在当中起了哪些作用。在 veth09b65e0 上进行 tcpdump 抓包:
|
接下来在宿主机上发送一个 http 请求: $ curl 外网IP:8003/index
观察抓包结果: tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on veth09b65e0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
13:20:07.776304 ARP, Request who-has 172.17.0.4 tell 172.17.0.1, length 28
13:20:07.776340 ARP, Reply 172.17.0.4 is-at f6:76:82:03:3c:11, length 28
13:20:07.776360 IP 172.17.0.1.45712 > 172.17.0.4.8080: Flags [S], seq 1479224415, win 64240, options [mss 1460,sackOK,TS val 3719423896 ecr 0,nop,wscale 7], length 0
13:20:07.776405 IP 172.17.0.4.8080 > 172.17.0.1.45712: Flags [S.], seq 948774028, ack 1479224416, win 65160, options [mss 1460,sackOK,TS val 2052977918 ecr 3719423896,nop,wscale 7], length 0
13:20:07.776432 IP 172.17.0.1.45712 > 172.17.0.4.8080: Flags [.], ack 1, win 502, options [nop,nop,TS val 3719423896 ecr 2052977918], length 0
13:20:07.777661 IP 172.17.0.1.45712 > 172.17.0.4.8080: Flags [P.], seq 1:84, ack 1, win 502, options [nop,nop,TS val 3719423897 ecr 2052977918], length 83: HTTP: GET /index HTTP/1.1
13:20:07.777710 IP 172.17.0.4.8080 > 172.17.0.1.45712: Flags [.], ack 84, win 509, options [nop,nop,TS val 2052977919 ecr 3719423897], length 0
13:20:07.778127 IP 172.17.0.4.8080 > 172.17.0.1.45712: Flags [P.], seq 1:137, ack 84, win 509, options [nop,nop,TS val 2052977919 ecr 3719423897], length 136: HTTP: HTTP/1.1 200 OK
13:20:07.778177 IP 172.17.0.1.45712 > 172.17.0.4.8080: Flags [.], ack 137, win 501, options [nop,nop,TS val 3719423897 ecr 2052977919], length 0
13:20:07.778741 IP 172.17.0.1.45712 > 172.17.0.4.8080: Flags [F.], seq 84, ack 137, win 501, options [nop,nop,TS val 3719423898 ecr 2052977919], length 0
13:20:07.778867 IP 172.17.0.4.8080 > 172.17.0.1.45712: Flags [F.], seq 137, ack 85, win 509, options [nop,nop,TS val 2052977920 ecr 3719423898], length 0
13:20:07.778897 IP 172.17.0.1.45712 > 172.17.0.4.8080: Flags [.], ack 138, win 501, options [nop,nop,TS val 3719423898 ecr 2052977920], length 0
从中可以看出,首先收到了一个 ARP 的请求,询问谁是
172.17.0.4,arp
是一个二层的协议,说明这是网桥在向局域网发起的询问。那么本机就是
arp 所要寻找的网络设备,回复一个 arp 响应给网桥(172.17.0.1 就是
docker0)。后续三行是一个 TCP 的三次握手的过程。后续的过程则是 HTTP
的数据发送。这里还不能看出 netfilter 是怎么做过滤转发的。
开启 iptables 的 debug 日志,具体的脚本在附录中,查看 netfilter
是怎么工作的。然后使用 dmesg 来查看 kernel 的日志。
|
我们从外部访问接口,可以看到经过 NAT 之后 IN
IPVS
平时更多听说的可能是叫 LVS,Linux Virtual Server,LVS 是一个项目,是使用 Linux 提供负载均衡的一种方案,而真正提供负载均衡功能的是 Linux 下的各种组件,其中 IPVS 就是 LVS 提供四层负载的一个工具。IPVS 与 Netfilter 一样,都是工作在内核态,且 IPVS 是基于 Netfilter 框架实现的,其可以在数据包到达四层协议栈时对数据包进行处理。
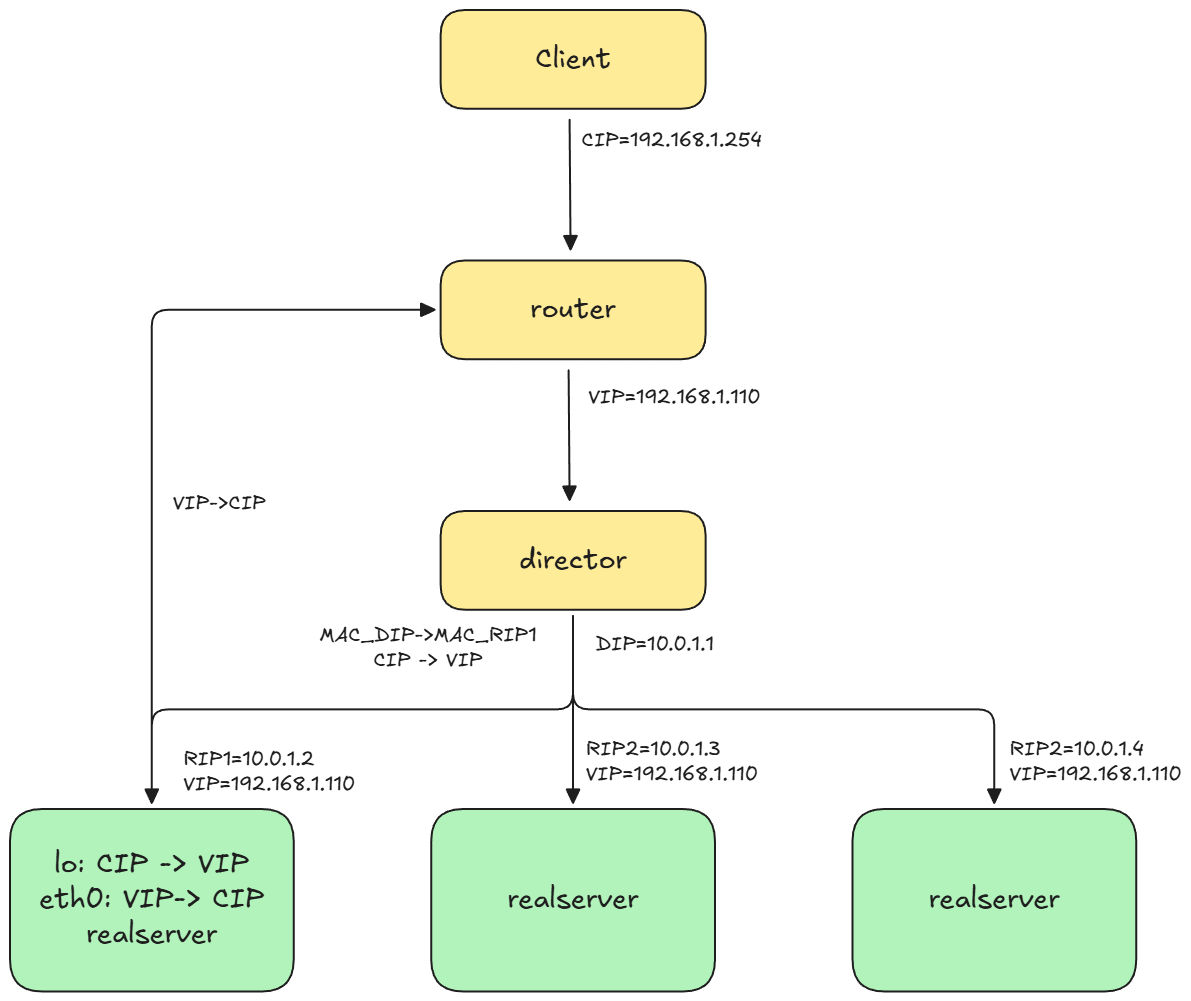
ipvs 不会做 DNAT,director 收到一个包后没有做 DNAT,而是直接将目标地址是虚 IP 的包直接发了出去。那么如何保证这个这个目标地址是虚 IP 的包能够被后面的真实 server 所接收。director 是通过修改包的 MAC 地址实现的。为了知道某一个 server 的 MAC 地址,那么就需要在局域网内广播发送 arp 请求。因此 director 和真实 server 必须在同一个局域网内。另一个问题是,真实 Server 收到一个目的 IP 是一个虚 IP 的包,想要处理这个包,那么自身也要有这个虚 IP。但是如果一旦设置了这个虚 IP,router 在广播找这个虚 IP 时,对应的 server 不能够回答,否则 director 的负载均衡机制就失效了。因此我们可以在真实 server 的本地回环网卡绑定一个虚 IP,或者是新建一个 dummy 网卡。回复包的时候直接把 client 的 IP 作为目的 IP,这样通过 router 进行路由,不用 director 做转交。
还是用三个容器来模拟环境: $ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
701fdfc1bf83 simpleserver "./main" 7 days ago Up 5 days 0.0.0.0:8003->8080/tcp, [::]:8003->8080/tcp simpleserver3
f8b056645289 simpleserver "./main" 7 days ago Up 5 days 0.0.0.0:8002->8080/tcp, [::]:8002->8080/tcp simpleserver2
af5f7c352bf5 simpleserver "./main" 7 days ago Up 5 days 0.0.0.0:8001->8080/tcp, [::]:8001->8080/tcp simpleserver1
先查一下所有容器的 ip 地址: $ docker inspect -f '{{.Name}} - {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' $(docker ps -aq)
/simpleserver3 - 172.17.0.2
/simpleserver2 - 172.17.0.3
/simpleserver1 - 172.17.0.4
创建一个虚 IP,并且添加一个 server 进去看看效果: ipvsadm -A -t 20.20.0.1:8080 -s rr-A:Add(添加),表示添加一个新的虚拟服务器。 -
-t:指定 TCP 协议的服务 -
20.20.0.1:8080:虚拟服务器的监听地址和端口 -
-s:指定调度算法(scheduler)。rr:Round
Robin(轮询)调度算法
|
-r 172.17.0.4:8080:指定真实服务器(Real Server)-g:指定模式为 DR
此时如果我们用虚 IP 去访问服务是访问不通的。重新加入一台机器,并对网卡进行抓包,观察一下出现了什么问题:
|
抓包结果如下: 23:30:51.993930 ARP, Request who-has iZuf6798j07zw8kchcz3mvZ tell _gateway, length 28
23:30:51.993944 ARP, Reply iZuf6798j07zw8kchcz3mvZ is-at 86:9e:b9:b7:87:ec (oui Unknown), length 28
23:30:51.993959 IP 172.18.72.188.45474 > 20.20.0.1.http-alt: Flags [S], seq 1016242174, win 64240, options [mss 1460,sackOK,TS val 2763844370 ecr 0,nop,wscale 7], length 0
23:30:51.993973 IP iZuf6798j07zw8kchcz3mvZ > 172.18.72.188: ICMP redirect 20.20.0.1 to host _gateway, length 68
23:30:51.993974 IP 172.18.72.188.45474 > 20.20.0.1.http-alt: Flags [S], seq 1016242174, win 64240, options [mss 1460,sackOK,TS val 2763844370 ecr 0,nop,wscale 7], length 0
23:30:53.011882 IP 172.18.72.188.45474 > 20.20.0.1.http-alt: Flags [S], seq 1016242174, win 64240, options [mss 1460,sackOK,TS val 2763845388 ecr 0,nop,wscale 7], length 0
23:30:53.011918 IP iZuf6798j07zw8kchcz3mvZ > 172.18.72.188: ICMP redirect 20.20.0.1 to host _gateway, length 68
会看到目的 IP 地址还是一个虚 IP 地址,这是因为 DR 模式下没有做 DNAT,所以容器没有办法处理这个包,因为容器无法识别这个虚 IP。我们可以手动把这个虚 IP 加到 lo 网卡上(所有节点):
|
此时在做对应的访问就能成功了: $ curl 20.20.0.1:8080/index
<h1>Hello World</h1>root
DR 模式比较严苛,要求 director 和 realserver 要处于同一个局域网之下。除此之外 ipvs 还有其他两种转发模式:
- NAT模式(Network Address Translation)
- IP隧道(IP tunneling)
从性能上来看 DR > NAT > IP隧道。
IPVS 常用的调度算法为:
- 轮询(Round Robin):IPVS认为集群内每台RS都是相同的,会轮流进行调度分发。从数据统计上看,RR模式是调度最均衡的。
- 加权轮询(Weighted Round Robin):IPVS会根据RS上配置的权重,将消息按权重比分发到不同的RS上。可以给性能更好的RS节点配置更高的权重,提升集群整体的性能。
- 最小连接数(Least Connections):IPVS会根据集群内每台RS的连接数统计情况,将消息调度到连接数最少的RS节点上。在长连接业务场景下,LC算法对于系统整体负载均衡的情况较好;但是在短连接业务场景下,由于连接会迅速释放,可能会导致消息每次都调度到同一个RS节点,造成严重的负载不均衡。
- 加权最小连接数(Weighted Least Connections):最小连接数算法的加权版~
- 地址哈希(Address Hash):LB上会保存一张哈希表,通过哈希映射将客户端和RS节点关联起来。
Service
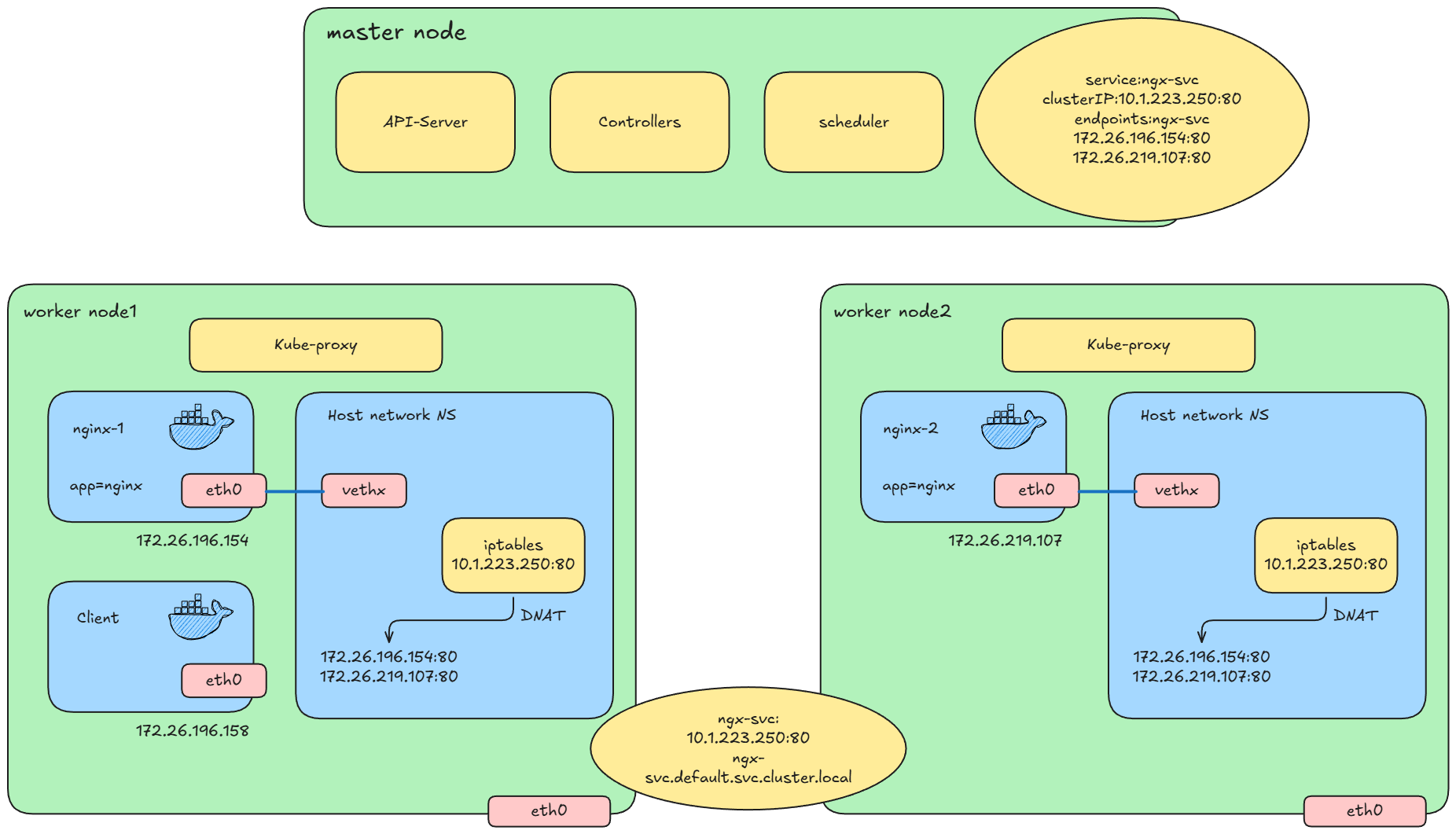
假设在一个客户端 Pod 中访问另一个 Nginx Pod,或者从主机去访问的时候。可以通过域名进行访问,域名通过内部的 dns 解析,得到对应 service 的 cluster ip。也就是通过 cluster ip 去访问。cluster ip 会从 iptables 做对应的 DNAT。会找到对应的一个 Pod IP。那么访问 Pod IP 就是之前提到的容器网络。因此 service 完成了从服务网络从容器网络的转换。
容器网络是如何实现的这里不做过多的讨论,具体依赖于所用的 CNI 插件,例如 calico 或者 flannel。
目前环境下有三台节点: [root@k8s-node1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready control-plane,master 272d v1.23.6
k8s-node2 Ready <none> 272d v1.23.6
k8s-node3 Ready <none> 272d v1.23.6
部署一下 nginx,对应的 yaml 在附录当中: [root@k8s-node1 yamls]# kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6f989c644f-gphwh 1/1 Running 0 2m9s 10.244.107.203 k8s-node3 <none> <none>
nginx-deployment-6f989c644f-wbzmw 1/1 Running 0 2m9s 10.244.169.140 k8s-node2 <none> <none>
再来创建一个 service: [root@k8s-node1 yamls]# kubectl get svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 272d <none>
ngx-svc ClusterIP 10.104.121.166 <none> 80/TCP 71s app=nginx
查看一下 service 对应的 endpoints: [root@k8s-node1 yamls]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.45.101:6443 272d
ngx-svc 10.244.107.203:80,10.244.169.140:80 2m16s
现在我们把一个 Pod 删除,会自动重新启动一个新的 Pod,对应 Pod 的 IP
地址会发生变化,那么 endpoints 也会发生变化,service 会更新这些信息:
[root@k8s-node1 yamls]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-6f989c644f-gphwh 1/1 Running 0 17m
nginx-deployment-6f989c644f-wbzmw 1/1 Running 0 17m
[root@k8s-node1 yamls]# kubectl delete pod nginx-deployment-6f989c644f-gphwh
pod "nginx-deployment-6f989c644f-gphwh" deleted
[root@k8s-node1 yamls]# kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6f989c644f-wbzmw 1/1 Running 0 18m 10.244.169.140 k8s-node2 <none> <none>
nginx-deployment-6f989c644f-wh5p7 1/1 Running 0 18s 10.244.107.204 k8s-node3 <none> <none>
[root@k8s-node1 yamls]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.45.101:6443 272d
ngx-svc 10.244.107.204:80,10.244.169.140:80 7m39s
查看 Kube-proxy 对 iptables 添加了什么路由规则: [root@k8s-node1 yamls]# iptables -t nat -L KUBE-SERVICES -n
Chain KUBE-SERVICES (2 references)
target prot opt source destination
KUBE-SVC-JD5MR3NA4I4DYORP tcp -- 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:metrics cluster IP */ tcp dpt:9153
KUBE-SVC-KASVC3VP5K2MBOHI tcp -- 0.0.0.0/0 10.104.121.166 /* default/ngx-svc:http cluster IP */ tcp dpt:80
KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- 0.0.0.0/0 10.96.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:443
KUBE-SVC-TCOU7JCQXEZGVUNU udp -- 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:53
KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- 0.0.0.0/0 10.96.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:53
KUBE-NODEPORTS all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
ngx-svc 的 ip 地址是
10.104.121.166:80,对应的会匹配到
KUBE-SVC-KASVC3VP5K2MBOHI 这条链上,查看一下
KUBE-SVC-KASVC3VP5K2MBOHI 这条链是什么内容:
|
KUBE-MARK-MASQ 当我们从主机访问 service
的时候,会走这条路由。而下面两条就是对应 endpoints
的负载均衡策略链路,选取其中一条查看:
|
当一个 Pod 通过 service 访问自己的时候,源地址和目标地址都是自己,这样的数据包可能会被 Linux 丢弃,所以有了第一条的路由规则。第二条做了 DNAT,这样就从 service 的 clusterIP 转换为 Pod IP 的过程。
Service 有四种种类:
- ClusterIP
- NodePort:允许外部流量通过
NodeIP:NodePort访问 Service - Headless
- LoadBalancer:在 NodePort 基础上,自动请求云提供商(如 AWS、GCP、Azure)分配一个外部负载均衡器。
- ExternalName:将 Service 映射到一个外部 DNS 名称(如数据库、第三方 API),不代理任何流量。
DNS
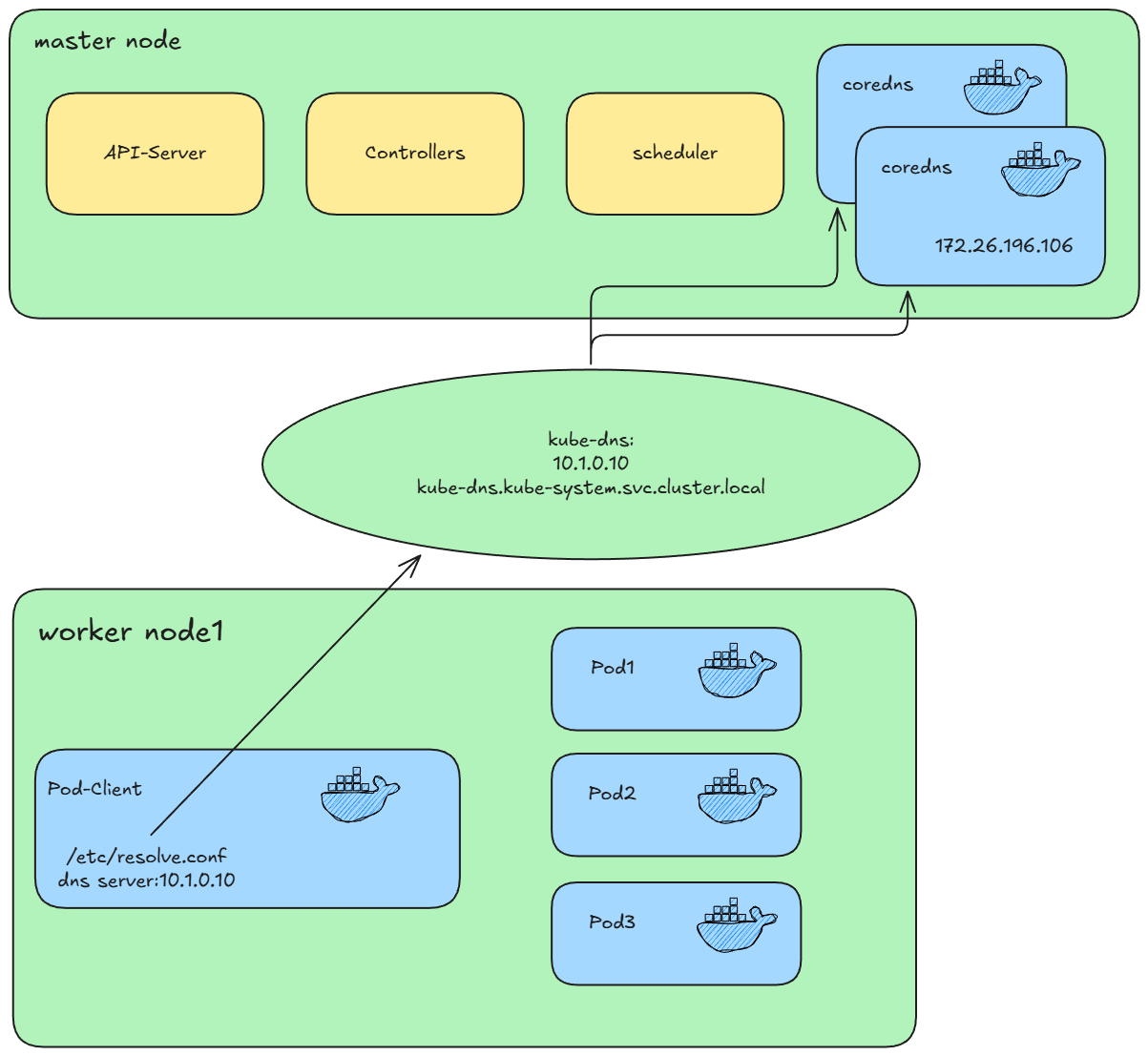
建立一个 service 的时候,会把对应的域名添加到 k8s
的域名服务器中。coredns 也是一个 Pod,k8s 中有一个默认的
service,kube-dns 就是为这一组 Pod 做负载均衡的。
附录
netfilter debug 脚本:
#!/bin/bash
iptables -t nat -I DOCKER 1 -p tcp --dport 8001 --syn -j LOG --log-prefix "BEFORE-DNAT-8001: " --log-level 4
iptables -t mangle -I OUTPUT 1 -p tcp -d 172.17.0.0/16 --dport 8080 --syn -j LOG --log-prefix "AFTER-DNAT-OUT-8080: " --log-level 4
iptables -t filter -I OUTPUT 1 -p tcp -d 172.17.0.0/16 --dport 8080 --syn -j LOG --log-prefix "AFTER-DNAT-FILTER-OUT-8080: " --log-level 4
iptables -t nat -I POSTROUTING 1 -p tcp -d 172.17.0.0/16 --dport 8080 --syn -j LOG --log-prefix "AFTER-DNAT-POST-8080: " --log-level 4
#!/bin/bash
iptables -t nat -D DOCKER -p tcp --dport 8001 --syn -j LOG --log-prefix "BEFORE-DNAT-8001: " --log-level 4
iptables -t mangle -D OUTPUT -p tcp -d 172.17.0.0/16 --dport 8080 --syn -j LOG --log-prefix "AFTER-DNAT-OUT-8080: " --log-level 4
iptables -t filter -D OUTPUT -p tcp -d 172.17.0.0/16 --dport 8080 --syn -j LOG --log-prefix "AFTER-DNAT-FILTER-OUT-8080: " --log-level 4
iptables -t nat -D POSTROUTING -p tcp -d 172.17.0.0/16 --dport 8080 --syn -j LOG --log-prefix "AFTER-DNAT-POST-8080: " --log-level 4
#!/bin/bash
iptables -t raw -I PREROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in raw.prerouting>"
iptables -t mangle -I PREROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.prerouting>"
iptables -t nat -I PREROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in nat.prerouting>"
iptables -t mangle -I INPUT -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.input>"
iptables -t filter -I INPUT -p tcp --dport 8080 -j LOG --log-prefix "target in filter.input>"
iptables -t raw -I OUTPUT -p tcp --dport 8080 -j LOG --log-prefix "target in raw.output>"
iptables -t mangle -I OUTPUT -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.output>"
iptables -t nat -I OUTPUT -p tcp --dport 8080 -j LOG --log-prefix "target in nat.output>"
iptables -t filter -I OUTPUT -p tcp --dport 8080 -j LOG --log-prefix "target in filter.output>"
iptables -t mangle -I FORWARD -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.forward>"
iptables -t filter -I FORWARD -p tcp --dport 8080 -j LOG --log-prefix "target in filter.forward>"
iptables -t mangle -I POSTROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.postrouting>"
iptables -t nat -I POSTROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in nat.postrouting>"
#!/bin/bash
iptables -t raw -D PREROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in raw.prerouting>"
iptables -t mangle -D PREROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.prerouting>"
iptables -t nat -D PREROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in nat.prerouting>"
iptables -t mangle -D INPUT -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.input>"
iptables -t filter -D INPUT -p tcp --dport 8080 -j LOG --log-prefix "target in filter.input>"
iptables -t raw -D OUTPUT -p tcp --dport 8080 -j LOG --log-prefix "target in raw.output>"
iptables -t mangle -D OUTPUT -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.output>"
iptables -t nat -D OUTPUT -p tcp --dport 8080 -j LOG --log-prefix "target in nat.output>"
iptables -t filter -D OUTPUT -p tcp --dport 8080 -j LOG --log-prefix "target in filter.output>"
iptables -t mangle -D FORWARD -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.forward>"
iptables -t filter -D FORWARD -p tcp --dport 8080 -j LOG --log-prefix "target in filter.forward>"
iptables -t mangle -D POSTROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in mangle.postrouting>"
iptables -t nat -D POSTROUTING -p tcp --dport 8080 -j LOG --log-prefix "target in nat.postrouting>"
nginx 部署文件: # nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2 # 指定 Pod 副本数为 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
resources:
requests:
memory: "64Mi"
cpu: "100m"
limits:
memory: "128Mi"
cpu: "200m"
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 15
periodSeconds: 20
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 10
nginx-service: apiVersion: v1
kind: Service
metadata:
name: ngx-svc
spec:
ports:
- name: http
port: 80
targetPort: 80
selector:
app: nginx
type: ClusterIP